





Prefer video? View this post on YouTube!
As a programmer, it is important to know the limits of any service that you’re using. In some cases, the limits of a particular service may make it unsuitable for the task at hand, such as using Route53 as a database. In other cases, the limit may alter how you structure your solution, such as how the 15 minute limit on Lambda execution time requires you to break down large work into smaller chunks.
In this post, we’ll talk about limits in DynamoDB. While the DynamoDB documentation has a long list of limits for the service, most of these are not going to drastically change how you use DynamoDB. For example, nested attributes can only go to 32 levels of depth, I’ve never found this to be a factor in building my applications.
However, there are a few limits you must understand to model properly in DynamoDB. If you’re not aware of them, you can run into a brick wall. But if you understand them and account for them, you remove the element of surprise once your app hits production.
Those limits are:
- The item size limit;
- The page size limit for Query and Scan operations; and
- The partition throughput limits.
Notice how these limits build on each other. The first is about an individual item, whereas the second is about a collection of items that are read together in a single request. Finally, the partition throughput limit is about the number and size of concurrent requests in a single DynamoDB partition.
In the sections below, we’ll walk through each limit, discuss why it exists, and undestand how it affects how you should model in DynamoDB. Finally, we will conclude with some thoughts on DynamoDB’s philosophy of limits and why they’re helping you.
Let’s get started.
DynamoDB item size limit
The first important limit to know is the item size limit. An individual record in DynamoDB is called an item, and a single DynamoDB item cannot exceed 400KB.
While 400KB is large enough for most normal database operations, it is significantly lower than the other options. MongoDB allows for documents to be 16MB, while Cassandra allows blobs of up to 2GB. And if you really want to get beefy, Postgres allows rows of up to 1.6TB (1600 columns X 1GB max per field)!
So what accounts for this limitation? DynamoDB is pointing you toward how you should model your data in an OLTP database.
Online transaction processing (or OLTP) systems are characterized by large amounts of small operations against a database. They describe most of how you interact with various services — fetch a LinkedIn profile, show my Twitter timeline, or view my Gmail inbox. For these operations, you want to quickly and efficiently filter on specific fields to find the information you want, such as a username or a Tweet ID. OLTP databases often make use of indexes on certain fields to make lookups faster as well as holding recently-accessed data in RAM.
You should have the relevant properties in your database to find the particular record you want. And if the rest of the information for that record is small, you can include that data there as well.
But if you have a large piece of data associated with your record, such as an image file, some user-submitted prose, or just a giant blob of JSON, it might not be best to store that directly in your database. You’ll clog up the RAM and churn your disk I/O as you read and write that blob.
Put the blob in an object store instead. Amazon S3 is a cheap, reliable way to store blobs of data. Your database record can include a pointer to the object in S3, and you can load it out when it’s needed. S3 has a better pricing model for reading and writing large blobs of data, and it won’t put extra strain on your database.
In addition to making you consider the price & performance implications of large blobs, the 400KB item limit also prevents you from making a data modeling mistake.
When modeling data in DynamoDB, you often denormalize your data. For example, in modeling one-to-many relationships, you may denormalize a collection of child records onto its parent item rather than splitting each child record out into a separate item. This can work well when the number of related items is bounded.
However, if the number of related items is unbounded (think of a customer’s orders in an e-commerce store, or a user’s tweets in Twitter), then you would want to consider other approaches to model this relationship. Without the item size limit, the access patterns around fetching the parent item would get slower and slower as the size of the denormalized relation grew. By imposing this limit, it forces you to consider the nature of the relationship upfront and use a different method if the relationship is unbounded.
In both of these situations, DynamoDB is saving you from reduced performance as your item size grows.
Page size limit for Query & Scan
While the first limit we discussed involved an individual item, the second limit involves a grouping of items.
DynamoDB has two APIs for fetching a range of items in a single request. The Query operation will fetch a range of items that have the same partition key, whereas the Scan operation will fetch a range of items from your entire table.
For both of these operations, there is a 1MB limit on the size of an individual request. If your Query parameters match more than 1MB of data or if you issue a Scan operation on a table that’s larger than 1MB, your request will return the initial matching items plus a LastEvaluatedKey property that can be used in the next request to read the next page.
Similar to the second reason for the item size limit, this page size limit forces you to reckon with the performance implications of your data model upfront. Paginated queries are one of the two areas you might see performance problems as your application grows. If you have an access pattern that uses Query and could result in more than 1MB of data being looked at, you need to account for pagination in your application code.
Accounting for pagination (by handling the LastEvaluatedKey and making follow-up requests) has a great property — it’s very easy to see understand which areas might slow down as your application grows.
If I’m doing a PR review and I see LastEvaluatedKey being used, my antenna goes up and I know I need to think about implications:
- How likely is it that we’ll need to page on this request?
- What are the maximum number of pages we’ll need?
- Do we want to allow multiple pages on a single request, or should we push that back to the client?
- Is there another way we can model to reliably reduce request size under 1MB?
The page size also fits in well with DynamoDB Filter Expressions (which you probably don’t want to use). The 1MB page limit applies before the Filter Expression is applied. DynamoDB is teaching us what the expensive parts of an operation are — finding and reading lots of data from disk.
Contrast this with other database engines. If you’re using any aggregate functions in Postgres or MongoDB’s aggregation pipeline, the code to execute the query can look deceptively simple. But that code is hiding some unknown performance implications under the hood. Aggregations require scanning all of the relevant data. This may be performant when we’re talking about hundreds of rows in your test environment, but it will crawl when you hit millions of rows at scale.
Partition throughput limits
We now know how big a single item can be. We know how much data a single request can read. Let’s close our discussion of limits with the partition throughput limits, which address how much data concurrent requests can handle.
To begin, you need to know some basics around how DynamoDB models its data.
A DynamoDB table isn’t running on some giant supercomputer in the cloud. Rather, your data will be split across multiple partitions. Each partition contains roughly 10GB of data.

Each item in your DynamoDB table will contain a primary key that includes a partition key. This partition key determines the partition on which that item will live. This allows for DynamoDB to provide fast, consistent performance as your application scales.
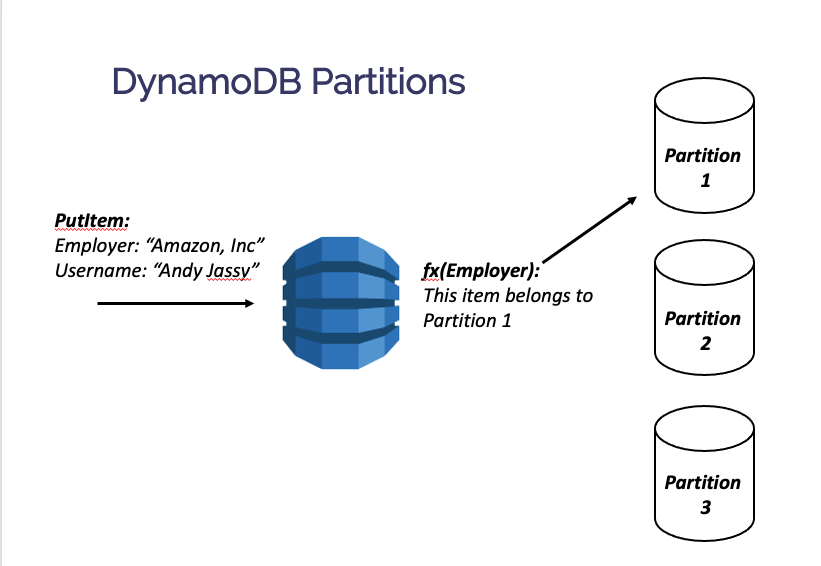
For additional background on partitions and how they help DynamoDB scale, check out Why NoSQL databases can scale horizontally.
For an individual partition, there are limits on the maximum throughput you can consume on a per-second basis. You can use up to 3,000 Read Capacity Units (RCUs) and up to 1,000 Write Capacity Units (WCUs) on a single partition per second.
Note — this is a lot of capacity! This would allow you to read 12MB of strongly-consistent data or 24MB of eventually-consistent data per second, as well as to write 1MB of data per second. And remember — this is per-partition! You can have significantly higher traffic across your table as a whole, and the maximum amount of capacity is effectively unbounded, assuming your credit card is good for it. For many DynamoDB users, they’ll never come close to these partitions limits on a full-table basis.
And yet, some users will blow past 3000 RCUs and 1000 WCUs on a table. And this limit helps to guide their data modeling. As you model a high-traffic table, you consider whether you will have partitions that exceed this limit. If so, you can model for it explicitly, whether using DAX to cache hot items or by sharding your partition key to spread the load across your table.
One final note in this area: the DynamoDB team has done a lot of work in the past few years to ensure that the partition throughput limits are the only thing you need to consider when thinking about traffic across your table.
In the old days of DynamoDB (pre-2018), DynamoDB would spread your provisioned throughput equally across all partitions in your table. This could lead to issues if your workload was unbalanced. Imagine you had certain keys that took more traffic than others — think of the distribution of popular tweets or Reddit threads. Because the throughput is spread equally, you could be getting throttled in one partition while you had capacity to burn in others.
This led to DynamoDB users needing to overprovision their tables to account for their hottest partitions rather than for overall traffic. By extension, you needed to care about two things: the partition throughout limit as well as your hottest partitions.
DynamoDB changed that with adaptive capacity. Adaptive capacity works by spreading your provisioned throughput across your table according to demand rather than spreading it evenly. If you have one partition taking more traffic, it will take capacity from one of your other partitions.
Initially, adaptive capacity would take 5 - 30 minutes to spread capacity across your table. In May 2019, adaptive capacity became instant, meaning you could have highly variable workloads from one second to another, and DynamoDB would spread your capacity accordingly.
There are two major implications of adaptive capacity. First, for all users, this meant less that you needed to think about. You don’t need to do the math to calculate the number of partitions in your table as well as the required throughput to give enough capacity to your hottest partition. You only need to consider overall throughput when doing capacity planning.
Second, this opened up some data modeling patterns for tables with lower traffic. Generally, you want to spread your data evenly across your partitions. However, this can make it harder to do queries that look at your entire table, such as finding all entities of a particular type or finding the top N items in the dataset.
If you won’t go anywhere near the partition throughput limits, you can create large partitions that handle these access patterns. You need to be absolutely sure you won’t hit them — otherwise you’re in for a nasty surprise at some point — but it can make it easier to handle these patterns.
The DynamoDB philosophy of limits
In the sections above, we’ve seen how these key limits are designed to point you in the proper direction for modeling your data. But they’re doing more than that — they’re reducing the complexity of understanding your database performance.
With traditional databases, your performance is on a spectrum. The response time for a query can vary significantly based on a number of factors — size of the dataset, the hardware running your database (including CPU, RAM, disk, and network bandwidth), and the other queries running at the same time.
This variability makes it very difficult to plan how your application will perform as it scales. Load tests that simulate actual traffic are difficult, particularly for a new service, so you may just roll something out there and pray for the best.
With DynamoDB, performance isn’t a spectrum. It’s binary — yes or no. You know the exact limits where your access patterns won’t work anymore, whether it’s due to pagination on your Query or throttling on your hot keys.
These limits surely aren’t the absolute maximum that DynamoDB can handle. We know that DynamoDB could handle items over 400KB — after all, they’re handling 1MB of data in Query & Scan operations!
And we know that DynamoDB could handle more than 1MB on a Query or Scan operation, as the BatchGetItem operation can return up to 16MB of data.
Finally, I’m sure DynamoDB could go beyond 3000 RCUs or 1000 WCUs on a single partition if it really wanted to push it.
But the key is that DynamoDB is drawing a line and guaranteeing performance everywhere before that line.
Your database has physical limits. If you don’t know what they are, you’re flirting with danger. I’ve personally experienced issues with Elasticsearch under high load where everything is going swimingly, then the entire database falls over suddenly and without warning. In Postgres, you might lock up your database with multi-transactions. And don’t get me started with MongoDB’s aggregation framework.
The more I work with other databases, the more I prefer the explicit limits of DynamoDB as compared to the unstated limits of other tools.
Conclusion
In this post, we covered the three limits that matter in DynamoDB. First, we saw the limit of an individual item. Next, we looked at the page size limit for Query and Scan operations. Then, we saw how the partition throughput limit regulates concurrent access to certain items.
Finally, we closed with some thoughts on how the DynamoDB limits are helping you. With most databases, performance is on a spectrum with a number of often-unknowable factors combining to determine your response time. With DynamoDB, performance is binary — as long as you fit within the limits, your performance is knowable.
If you have questions or comments on this piece, feel free to leave a note below or email me directly.

















